OpeNER Architecture
The OpeNER project set out as a EU subsidized FP7 project with the goal to level the playingfield in NLP technologies, and provide SME and research organisations with a relatively easy entrance into the field. During 2 years a group of over 30 people worked to create, tune, wrap up and improve upon a set of NLP tools, techniques, datasets and toolkits for 6 languages.
OpeNER therefore is much more than “a piece of software”. It’s actually a collection of tools, techniques, datasets, hard-core language tech and integration layers that combined give the whole industry a platform to start using NLP technologies, improve upon them and keep on innovating and extending.
Therefore this document is split in 5 sections:
- Project Architecture
- Technical Architecture
- Implementation Details
- Social Architecture
- Where to go from here
OpeNER Project Architecture
The picture below provides an overview of the different kind of stakeholders and parts that are involved in the project. More detailed information on each block can be found at the Documentation Page.
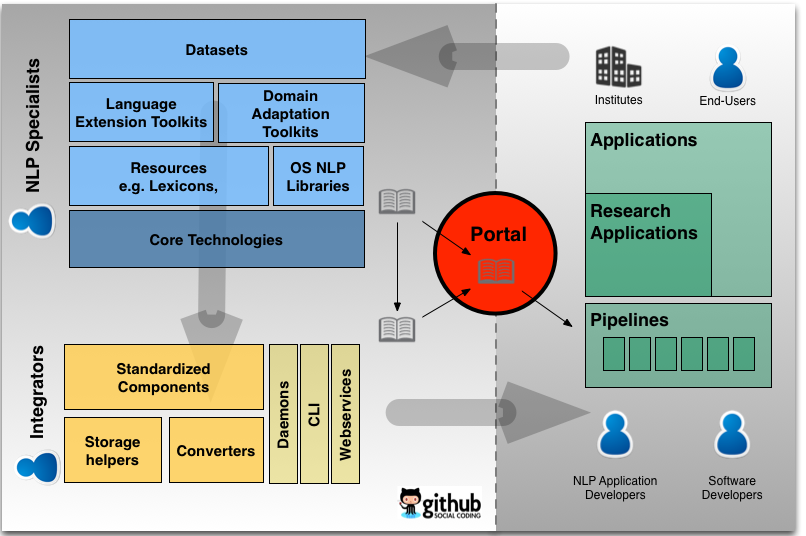
OpeNER Technical Architecture
OpeNER is based on 3 layers where each layer is specifically tuned into one of the stakeholders of the NLP field: Application Specialists, Integrators and NLP Specialists. The three layers are:
-
Pipelines: A set of software components working together to achieve a certain NLP tasks, like opinion detection or named entity recognition. The pipeline layer is used by application specialists.
-
Components: Software that bundles 1 or more core technologies that perform an NLP task, for example a part-of-speech tagging. A component wraps 1 or more language cores in a layer that consists of a command line interface, a web-service and a standalone daemon as well as installer scripts. The components are the building blocks of pipelines and are created by the integrators.
-
Language Cores (cores): Software programs that performs a single NLP task for 1 or more languages. Cores are the actual “working part” of OpeNER components and pipelines. Cores are created by NLP specialist using a programming language and libraries of their own choice.
The language cores use a variety of programming languages to achieve their goal, currently there are cores written in Java, Python and Perl. Those get “wrapped up” in the components using a layer of Ruby glue. The Ruby glue provides at least 3 standard interfaces:
- A command line interface
- A webservice
- A daemonized interface
The main concepts OpeNER technology are displayed below.
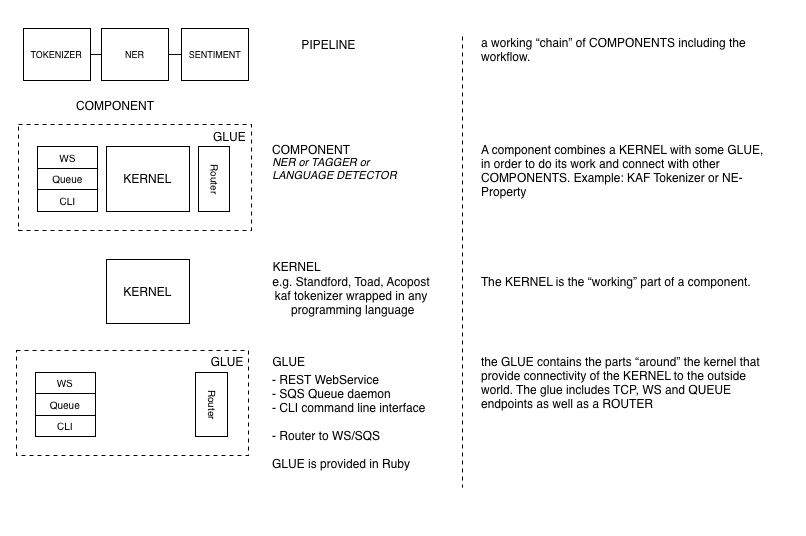
Pipelines
In order to analyze unstructured text and turn it into something we can analyze using computers we need to process the text using a selection of NLP tools. A relatively standard series of steps might look like this:
- Language identification: Are we actually dealing with a text for which we have to right tools?
- Tokenization: split the text into paragraphs, sentences and words.
- Part-of-speech tagging: Determine what kind of words are in the text, verbs, nouns etc.
- Lemmatize: Finding the word stem. The “am” in the phrase “I am” will be brought back to the full verb “be” for example.
After that follow the more complicated tasks like detecting words that carry a certain sentiment (polarity tagging), of figuring out which words resemble names of people an places (named entity recognition).
When an end-users goals is to find opinions in text, they are constructing pipelines out of OpeNER components. These components can be chained together by means of “piping” commands on a unix command line, by using a callback system using web-services or by using queue systems and daemons. Mixing and matching is possible to.
As described in the requirements one can gradually grow into the creation of pipelines. Let’s say we want to analyze a half a million hotel reviews and see what the most talked about topic is. In order to develop such a pipeline one would normally first take a quick look at what the OpeNER components give us using the command line tools or the web-services available at the project homepage.
The command line tools are great to play around with the order of components and specific settings or dictionaries. Once you know what the pipeline should look like you can launch every single component as a web-server. Out of the box all OpeNER components ship with the right tools to launch a web-service using only a single command.
The web-services can be chained together using a callback mechanism, as will be explained in section [section number here]. Combined the web-services will give you a processing pipeline capable of processing hundreds of documents an hour. However, when you number of reviews goes up in to the thousands, hundreds of thousands or even millions, the overhead of http web-services becomes too big, you need a different approach: daemons.
Just like every component ships with a command line interface and a web-service, all components ship with a daemon. A daemon is a program that runs in the background of your computer and server. It continuously monitors an online queue. If there are jobs in the queue for the daemon, it processes the document and stores the result in the following queue, or the database. You can launch as many daemons as you need, they can all read from the same queue.
This ultimately means that you have a virtually unlimited amount of power available to process your texts. You simply launch as many daemons as needed to process your documents within the timeframe you yourself pick. Daemons also give you the options to fine tune the scaling of your analysis to the tasks at hand, for example, language identification is a very fast task, while property tagging is much slower. In this case you could launch 1 language-identification daemon and 4 property tagger daemons. Daemons are the ultimate form of distributed NLP and in our experiments we’ve been processing millions of documents at a fraction of the cost and time other commercial and open source applications can do this.
The gradual stiffening of the pipeline is made possible by the generic interfaces provided by the OpeNER component glue and middleware.
Components
The real architectural innovation of the OpeNER framework lies in the component middleware. Each OpeNER component wraps 1 or more language cores. For example, the OpeNER reference implementation of the part-of-speech tagger component (POS-tagger) combines 2 language cores in a single piece of software:
- a core, written in python, that is capable of processing Dutch and German
- texts, and a core, written in Java, that is capable of doing English, French,
- Italian and Spanish.
As an end-user, by using the component, you won’t see the difference between these cores. The component abstracts this away from you. If you provide the POS-tagger with a Dutch text, it will use the python libraries, and when presented with a Spanish text it will switch to the Java implementation. The performance might differ, but the overall use does not.
Components do not only abstract away the use of the individual language cores, they also abstract away a lot of the installation hassle you normally find when having to install a large collections of tools. Given that the installers of the language components work properly (more on this in the next section), installing a multi-language pos-tagger, named entity disambiguation or opinion detector actually will be as easy as a 1 liner.
Interfaces
Every component wraps the cores in a layer that provides 3 standardized interfaces:
- A Command Line Interface (CLI) a self contained web-service which is also
- mountable into larger server setups, and a daemon capable of reading from
- Amazons queue system SQS.
It is important to note that the original language cores do not have to support any of these interfaces. As long as the language cores comply with the basic OpeNER requirements presented in the next section, a CLI, web-service and Daemon will be provided “for free” by the standard OpeNER middleware component tools. This turns basically any piece of NLP software into a working component that is linearly scalable and gradually stiffens in it’s use.
The command line interface is used for quick evaluations and one off samples. It is easy to use and provides a very flexible “unixy” way of composing NLP pipelines. It will not be the most performant option, but is works, is easy to understand and debug and provides great insight into the workings of a pipeline.
One step up is the web-service. Each component can launch itself as a self-contained web-services. No web-servers like Nginx or Apache are necessary. However, when one want to move away from single web-services running on small computers, towards a more professional setup with a server, possibly behind a load balances, this is possible too. The web-services can be mounted as “rack applications” in larger server setups. As with the OpeNER system in general thresholds of starting to use a web-service are low, but the system tries to gradually stiffen up and support you when scaling your research or application.
While command line interfaces are suitable for “playing around” and prototyping, and web-services are a convenient option for on the fly “real time” processing of documents, both these systems are not scalable to “big data” or “web-scale”. In order to achieve reliability and resilience when processing hundreds of thousands or millions of document a different approach is needed: Daemons reading from queues.
The basic principle is easy to grasp: You put a large number of texts into a queueing system like Amazons SQS system and you launch a daemon that pops a message of the queue. The daemon processes the message and puts the results into the next queue or into a database or other storage facility like Amazon S3. If your pipeline consists of n steps you need n queues and a storage option.
More on the specific queues and storage facilities we use can be found in the section on “resilience is in the queues” [section reference here]
Method of integration
Next to the standard interfaces of components, components also enforce the standardization of the input and output formats. Each component understands texts represented in the KAF XML format, and outputs its results using the same format.
Both the interface as well as the format integrations and standardizations are achieved because the components the language cores, follow 2 simple rules: a) a language core reads input from STDIN and b) a language core outputs to STDOUT
Wrapping language cores using STDIN and STDOUT might not be the best performing way of integrating language cores but it provides us with a baseline that works for every programming language and framework; it gets the job done. Once basic integrations are in place, you can actually work on improving the performance of the integration.
An example of this is the POS-tagger component in the reference implementation. The POS-tagger in the reference implementation bundles a Java based POS-tagger language core for French, Italian, Spanish and English with a Python based POS-tagger language core that handles Dutch and German. During the initial component integration both cores were implemented using the STDIN / STDOUT principle. This however lead to a very slow POS tagger for the languages that were implemented in the Java based POS tagger. Since every time a text was processed we needed to boot the Java Virtual Machine (JVM) which takes several seconds. However, by switching over the middleware layer to a Java compatible scripting language we managed to run the Java based languages through an already booted and warmed up JVM and maintain running the python language core using the STDIN and STDOUT method.
Language Cores
The language cores are the working parts of the OpeNER system. Each of these language cores does “its own thing” and has its own perks, specific uses and implementations. That’s a good thing, and very fundamental to the success of the architecture. The language cores contain Java, Python, Perl or any other code that “gets the task done”. For example, we have a part-of-speech tagger implemented in Java using the popular Apache OpenNLP library. But we also have a part-of-speech tagger, specifically for Dutch and German implemented in Python using another popular toolkit called Tree Tagger.
NLP experts write their own software or mixed and matched the proper libraries and tools together from their ecosystem of choice, for example Java with OpeNLP or Python with Tree Tagger. As long as in the end, the result is software that complies with a very basic rule, it can be fit into the OpeNER architecture:
language cores read their input data from STDIN and output data to STDOUT
Even though it is technically possible to wrap language cores that do not comply with this rule, it makes the life of the integrators much easier if it the language cores play according to the rules.
Each language core, the piece of java, python, perl and all dependencies, is wrapped in a thin layer of Ruby. This layer has 4 functions, non of which directly impact the development or implementation of the language core itself.
- It makes sure that the language cores adhere to the 2 rules (or makes the core comply if it doesn’t)
- It provides versioning and packaging information used by the components to pick the right cores.
- It provides any install scripts needed to ship the language core with “batteries included”.
- It provides a testing framework for high level input-output tests.
The input-output tests are setup using fixture files. These fixture files contain an input document and have a corresponding output fixture containing the output one would expect to see if the input is processed properly by the core. By providing fixture files with the language core, the integrators can actually test if the integration of the core into the components works as expected. By taking the fixture files from the core, and feeding them into the component, one should still see the same output.
In everyday use, for end-users creating pipelines, one hardly ever has to touch the language cores, their installers or their implementation. Since users will actually string integrated components together as opposed to the language cores. However, it is of course possible to tune pipelines for certain languages and components, propagating specific options from a pipeline configuration, for example lexicon locations, all the way down through the components to the language cores.
Implementation Details
Ruby
The language of choice for all non language core integrations is Ruby.
Ruby is a super glue, it is an extremely versatile language and comes with the right ecosystem to implement all needed middleware efficiently. Standard Ruby implementations can bind to C and C++ libraries allowing for integrations that are faster than the STDIN / STDOUT route, while Ruby implemented on top of the JVM, called JRuby, actually makes it possible to call Java code straight from Ruby. This allows for component-to-core integrations with “native” JVM performance.
Ruby originated as a scripting language that took it’s lessons from languages suck as Perl, Smalltalk and Lisp, with a strong focus on system administration and automation, but thanks to Twitter using Ruby in their first implementations, the language also developed a large ecosystem of web-capable components and libraries. This combination makes that ruby was the cut out choice for the middleware layer.
The Ruby ecosystem furthermore comes with a package management tool called RubyGems and a dependency manager called bundler. Combined these tools make that wrapping language cores with a thick layer of CLI, web-service, Daemon and installer tools is actually rather easy. With a bit of practice wrapping any language core into a component, including all the luxury, takes less than 30 minutes.
While explaining the intricate details of the middleware implementations in Ruby lies beyond the scope of this document, we do encourage the technically savvy reader to checkout the documentation on the OpeNER Project portal (www.opener-project.eu) as well as the source code of the reference implementations on Github.
Component to Component communication
To make it possible for any OpeNER component to communicate with other OpeNER components we defined a basic input and output rule for components, much like we did for the language cores.
Each OpeNER component is able to read a standard input format and output in the same standard format
This meant we needed a standard format to represent the semantic annotations done by OpeNER tools. Because of prior and positive experiences we chose KAF to be this standard. KAF is a generic semantic annotation format, implemented in XML, that is very suitable to represent the information you would normally like to annotate NLP toolchains. It was developed as part of the Kyoto Project (http://kyoto-project.eu/xmlgroup.iit.cnr.it/kyoto/index.html) and stands for Kyoto Annotation Format.
A KAF XML is structured in layers. Each layer is usually the result of a particular analysis module of the chain. Some layers have pointers to other layers’ elements through the elements’ ids, which is done using “span” elements. Also some layers (the more basic ones) are a prerequisite for the processes that produce some other layers (the more advanced ones).
The most easy KAF document basically only contains the raw text contained in
<KAF> tags. Then, after the text has been split into tokens like words and
sentences, the KAF document will contain some meta information on which process
did the tokenization as well as the results from the tokenization. Extensive
examples and more information on the reasoning behind KAF can be found at the
Kyoto project website, the KAF wiki
(https://github.com/opener-project/kaf/wiki/KAF-structure-overview) and the
original publication on KAF by Bosma et. al (2009)[reference!]
There are of course alternatives to KAF. From a technical perspective you might look at a replacement of XML for JSON (Javascript Object Notation) or Google’s protocol buffers. And from a semantic point of view RDF and CONLL could have been considered, just as LAF and GAF, however, these formats didn’t seem to support all needed annotations out of the box, so we deemed it easier to change and update a format OpeNER consortium partners were very familiar with and that was present at the moment (KAF) as opposed to try and shape formats maintained by others.
However, this does not mean parsing into other formats is not possible. Given the general idea behind the OpeNER project, to unify and not diversify, you are not technically limited to the KAF format. As part of the OpeNER project converters have been created between KAF and its successor NAF. As well as between an XML and JSON representation of KAF documents. We do expect more converters to be added in the near future.
Batteries Included
OpeNER components and language components come, as much as possible, with their batteries included. This means that all required libraries and external software dependencies get installed at the same time a component and the cores it depends on gets installed.
The batteries included functionality is provided by the thin Ruby wrapper around the language cores. The amount of effort needed to achieve this varies per language core. Where Java based components can get a lot of help by using tools like Maven, other language ecosystems have not evolved that much. This is especially the case for Python based language cores that depend on libraries not compatible with pythons own library installation tool pip.
Challenges can be found when is bundling large datasets or extensive toolkits. The reference implementation of the Named Entity Disambiguation for example depends on a DBPedia server being up and running. In this particular case we chose to point to publicly available test servers of DBPedia instead of delivering a DBPedia installer ourselves.
Another decision we had to make is weather or not to ship large toolkits that themselves need a large network of dependencies. An example of such a toolkit is the Dutch dependency parser called Alpino. It is reportedly the best at it’s task [ask reference to Piek / Ruben], but also notoriously difficult to install and very large (Gigabytes).
A third example of a “batteries included” trade-off is the inclusion of very popular but large packages like Pythons “lxml” library. This library takes a long time to install, due to it’s compiled nature, and most probably is already present at the users machine. While we experimented with including Lxml packages in the python based language cores, we in the end decided to simply require lxml as a prerequisite for the user.
In all three cases above we had to trade of “absolute control over the users experience” with install speed and ease of integration. For example, including lxml as a battery included with the python based language cores increased their install time with minutes, not seconds. And adding a DBPedia installation as “batteries included” would actually mean downloading gigabytes of data.
Resilience is in the queues
Command line interfaces
The command line interfaces of the OpeNER components provide an easy entry into OpeNER Pipelines. An example of a pipeline setup using the command line interfaces might look like this:
cat hotel_review.txt | language-identifier | tokenizer | pos-tagger | property-tagger
This command will read the text in the hotel_review.txt and return the
review in the KAF XML format containing a list of detected properties of the
hotel, like the bathroom, the bar or the air-conditioner. It works by piping in
the output from the various components to the input of the next component.
Using standard unix command line tools the OpeNER components can be used for quick evaluations of documents and pipelines.
Webservices
A step up from the command line are the web-services. The easiest way to do is to use the available online web-services or launch our own web-services. Each OpeNER component ships with a web-service included. With a single command we can launch a language-identification web-service.
language-identifier-server
When this step is repeated for all components individually, we can then POST any text to the language-identifier, which will respond with the appropriate KAF response.
It is also possible to chain web-services together using a callback mechanism, with which you tell the first component in a pipeline to send its results to the 2nd, which will send it to the 3rd, and so on, until in the end the result gets stored. Using this mechanism the web-services function as an asynchronous pipeline.
Using a widely available command line tool like “puts” a pipeline identical to the command line pipeline indicated above could be executed using the following command. This command will return an output url at which you can request the final result.
shell cat hotel_review.txt | curl -F 'input=<-' \
"http://opener.olery.com/language-identifier\
?callbacks\[\]=http://opener.olery.com/tokenizer\
&callbacks\[\]=http://opener.olery.com/pos-tagger\
&callbacks\[\]=http://opener.olery.com/property-tagger\
&callbacks\[\]=http://opener.olery.com/outlet"
The odd service in this list is the outlet. The outlet is a web-service that stores the results it receives and displays those results upon request. The indented use of the outlet is to have it reside on your own servers. This way you will get automatic notifications when the results are in.
Using this concept it is actually possible to create pipelines using a mix of freely available, proprietary and possible locally improved versions of OpeNER compatible web-services. This could be useful when doing research on specific components, where one want to make sure that any differences in the final results are actually due to changes in the component under investigation, not due to changes into related components.
Another example could be the use of 3rd part and externally hosted web-services be it commercial entities (enabling authorization is trivial) or research organizations. The following hypothetical command would use software of 5 different parties to compute a result:
shell cat some_file.txt | curl -F 'input=<-' \
"http://opener.olery.com/language-identifier\
?callbacks\[\]=http://opener.olery.com/tokenizer\
&callbacks\[\]=http://some.university.edu/pos-tagger\
&callbacks\[\]=http://www.company.com/polarity-tagger\
&callbacks\[\]=http://www.example.com/opinion-detector\
&callbacks\[\]=http://your.own.comany.com/outlet"
Error Handling
Because of the distributed nature of the web-services, it is hard to catch any error that occur while a text is being processed. In order to provide some form of visibility one can submit an Error URL to which any error messages will be posted.
This might look like this:
shell cat some_file.txt | curl -F 'input=<-' \
"http://opener.olery.com/language-identifier\
?callbacks\[\]=http://opener.olery.com/tokenizer\
?error_callback=http://www.example.com/errors
Besides offering an error callback the OpeNER components are setup in a way that they pass along the original input they received, if they cannot process the input properly. This means that any failing component in a pipeline will not break the full pipeline. Of course, cascading errors might occur. When a language identifier fails, the other components simply don’t know which language to pick, but if a component breaks that is unrelated to another component in the chain, the pipeline keeps on processing.
OpeNER Social Architecture
As can be seen from the Project Architecture, there are a lot of different people involved in the project and all those people have a different set of expertise. This is what we embrace and accept.
- NLP specialists are not necessarily the best (web)developers
- (web)developers are not necessarily NLP experts
- Application Integrators are not necesarily the integration experts
Aknowledgeing this shaped a lot of the design decisions in the project. We very much focus on the fact that everybody should do what they do best, and that by agreeing on some very basic techniques people can work together and build on top of each others strengths.
Some examples of tech choices made because of their social and collaborative implications are:
- Language Core Technology is able to read from STDIN and outputs to STDOUT, not the most efficient way of doing things, but it works, always. Improvements can be made later. You don’t have to be expert developer to read from STDIN and output to STDOUT.
- Component to component communications are done using the KAF standard. If you don’t like KAF, that’s not a problem. Converters are present, it doesn’t matter how you represent the documents internally, just convert them back to KAF once you output results back into a pipeline. This way integrators don’t have to learn half a dozen NLP document formats.
- Components ship with “batteries included” often shipping their own versions of certain libraries that are potentially already available at the users machine. Still, we prefer ease of installation and packaging over resource optimization. If somebody wants to optimize resources and they have the knowledge, there are ways to do this and everybody is willing to help. However, as an application developer wanting to integrate “simple NLP” you shouldn’t need to jump through the installation of libraries and all kinds of machine learning and resource hoops.
- All language-cores ship with input and output fixtures, so that anybody down the chain can test if their integrations are working without breaking the core technologies. Since people “down the line” often have no clue how to check if the language core components are working as intended, input and out fixtures should be made available for all language cores.
More extensive documentation on some of the social aspects and how this influenced the design of OpeNER can be found on the Design Decisions page.
Conclusion
OpeNER plays well with current NLP tools and does not require the community to learn a lot of new languages or frameworks. The layered architecture plays to the strengths of all parties involved: scholars, business and individuals alike.
We aim to provide a system that allows researchers the freedom needed to write NLP implementations in the programming language they pick, and use the libraries of their own choosing, while also being clear on how to wrap their technology into components that can be easily distributed, installed, versioned and chained together.
By following several non-intrusive heuristics NLP technology experts get the luxury of an implementation that functions asa command line tool, a web-service or as a daemon process straight out of the box.
Ultimately this means that OpeNER provides an architecture and guidelines that turn arbitrary NLP implementations into highly scalable, inter operational building blocks of multi-lingual NLP pipelines. All of this, in order to make sure more people can contribute and reliably use the vast body of knowledge
Where to go from here?
Jump straight in and:
- Start using the webservices
- Setup a local installation
- Browse through an OpeNER Component
- Ask for help support@opener-project.eu
You might also be interested in some of the more extensive narratives on the project. You can find those in the Deliverables Section as well as on the Design Decisions page.